Updating all 70B parameters of a model needs hundreds of GB of optimizer state and a copy of the model per task. Parameter-efficient fine-tuning (PEFT) asks: how little can we train and still steer the model? The answer is usually under 1%.
LORA
Low-Rank Adaptation: learn the difference, factored
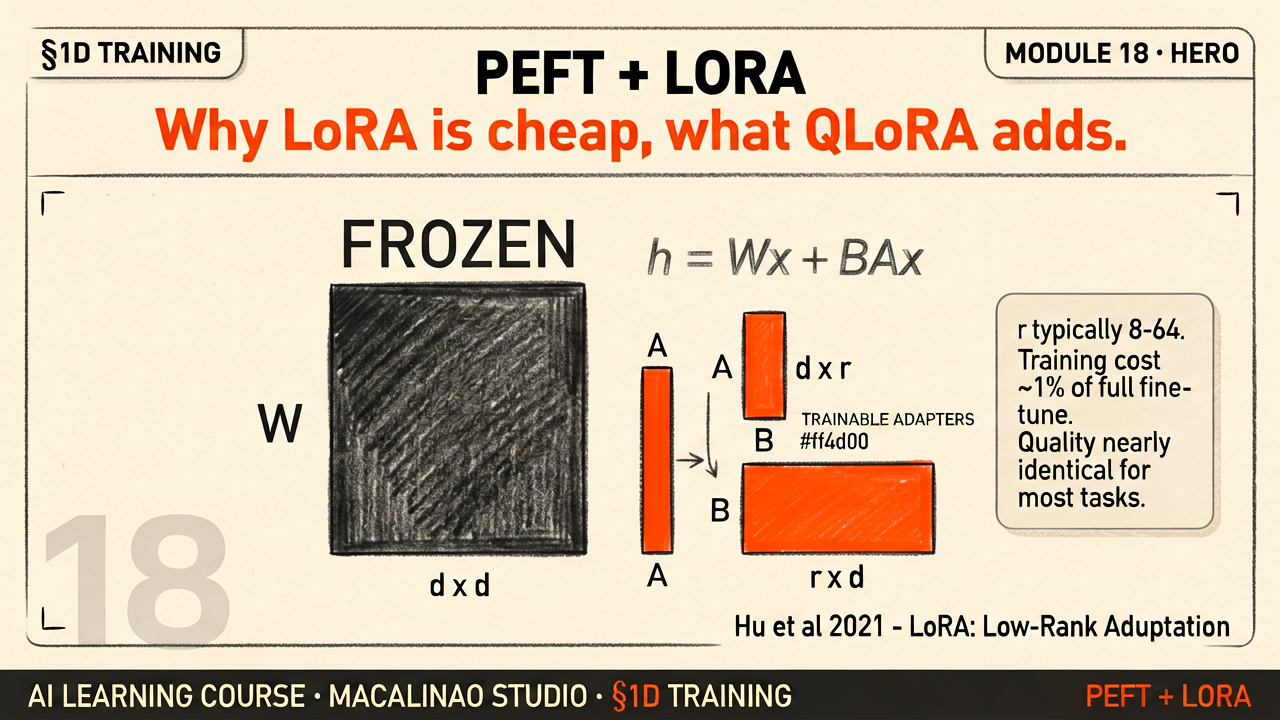
LoRA freezes the original weight matrix W and learns the update as two thin matrices: ΔW = B·A where A is r×d and B is d×r with rank r as small as 8–64. A 4096×4096 layer (16.7M weights) gets a rank-16 adapter of just 131k weights — 0.8% of the original. At inference, W + BA merges back so there is zero extra latency.
QLORA
QLoRA: train adapters on a quantized base
QLoRA keeps the frozen base in 4-bit NF4 while the LoRA adapters train in 16-bit. A 70B model that needs 140 GB in fp16 fits in ~40 GB — fine-tuning that once took an A100 cluster runs on a single consumer GPU. Example: this studio's character LoRAs train on RTX 3090s exactly this way.
RANK
Rank is the capacity dial
Low rank (4–16) is enough for style and persona; higher rank (64–256) is needed when the task adds real knowledge or new languages. Too high wastes memory and can overfit; too low underfits. The playground below lets you feel this trade-off directly.
SERVING
One base model, a rack of hot-swapped adapters
Because the base stays frozen, production servers (vLLM, LoRAX) load one copy of the weights and swap LoRA adapters per request — dozens of fine-tunes for the VRAM of one model. Know the limits too: for large-scale knowledge injection or RL fine-tuning, full-parameter training still outperforms adapters — LoRA steers, it doesn't re-educate.
§ 02
The lesson
The Frozen Brain (LoRA) To teach a massive 70B-parameter Base Model a new skill, we could update all its weights (Full Fine-Tuning) — but that requires clusters of extremely expensive GPUs. LoRA (Low-Rank Adaptation) freezes the big brain entirely and only trains a tiny "backpack" matrix of weights attached to it. The forward pass becomes: h = W₀x + (α/r)BAx .
§ 03
The playground.
Theory above, instrument below. This interactive panel runs live in the page — drag, type, and watch the mechanism respond.