Robust speech recognition via large-scale weak supervision · alignment timestamps
WHISPEROpenAI's STT model, trained on 680K hours of weakly-supervised audio
Whisper (Radford et al. 2022) is an encoder-decoder transformer trained on 680,000 hours of multilingual audio paired with transcripts. The scale and diversity of training data is what gives it robustness — it handles accents, background noise, and 99 languages without retraining. Five sizes available (tiny 39M, base 74M, small 244M, medium 769M, large 1550M). large-v3 (Nov 2023) was the long-running production standard; large-v3-turbo, with 8× faster decoding, is the 2026 self-hosting default. Whisper is no longer the accuracy frontier — NVIDIA Parakeet/Canary-class models top the open leaderboards, with Deepgram, AssemblyAI, and gpt-4o-transcribe on the API side, and streaming STT now serves live agents. One standing caveat: Whisper hallucinates fluent text on silence or music, so gate inputs with VAD.
INPUT REPRESENTATIONLog-mel spectrogram input, 30-second windows
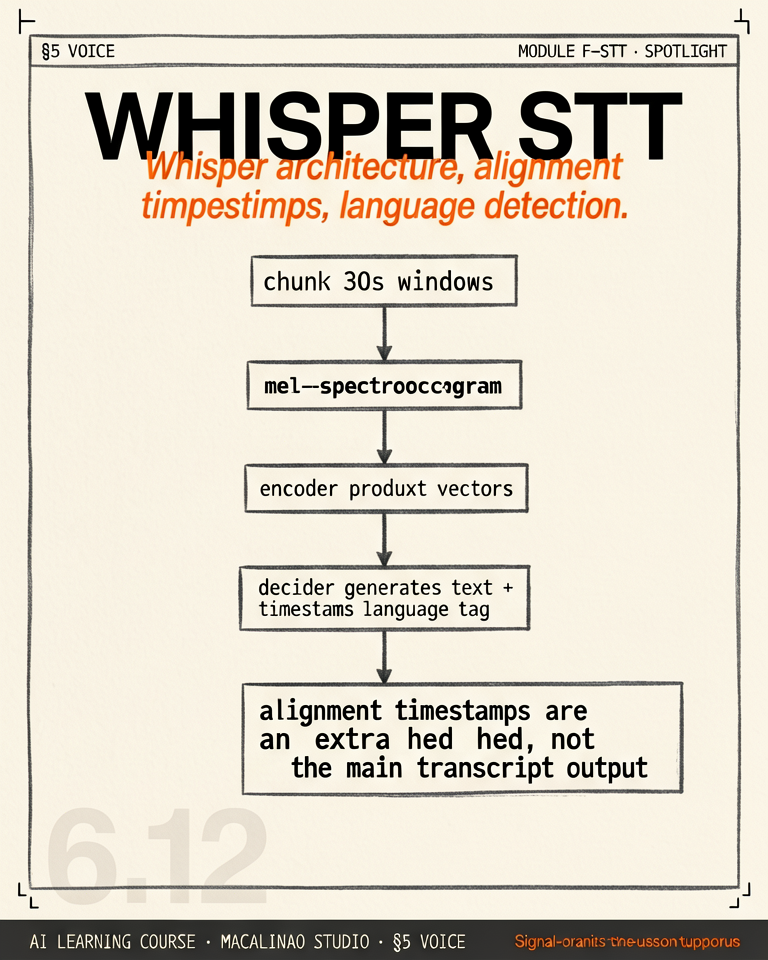
Whisper doesn't ingest raw audio. Audio is resampled to 16kHz, converted to a log-mel spectrogram (80 mel bins in v1/v2; 128 in large-v3), and chunked into 30-second windows. Each window becomes a sequence of 1500 "tokens" (3000 ms-frames at 100Hz, downsampled). The encoder transforms these into hidden states; the decoder generates the transcript token-by-token, attending to the encoder via cross-attention.
TIMESTAMPSSegment-level timestamps; word-level takes extra work
Whisper learns to predict timestamp tokens (0.02-second granularity) interleaved with transcript tokens — but these mark segment boundaries, not individual words. Word-level timing comes from cross-attention DTW (word_timestamps=True) or from WhisperX-style forced alignment with a smaller acoustic model, which refines timestamps to ~10ms precision — necessary for subtitle creation or lip-sync.
DEPLOYMENT REALITYfaster-whisper, whisper.cpp, distil-whisper
The reference PyTorch implementation is slow. faster-whisper (CTranslate2 backend) gives 4× speedup. whisper.cpp ports the model to CPU with no Python dependencies — runs in real time on a laptop. distil-whisper (HF 2023) keeps the encoder frozen and shrinks the decoder to 2 layers — decoding is the bottleneck — for 6× faster inference at 99% of the accuracy. The studio TTS/STT Audio Sync pipeline uses faster-whisper for batch jobs, whisper.cpp for live transcription.