Lightricks LTX-Video · what's inside a modern video diffusion model · motion control
LTX-VIDEO
Lightricks' open-weight video diffusion line
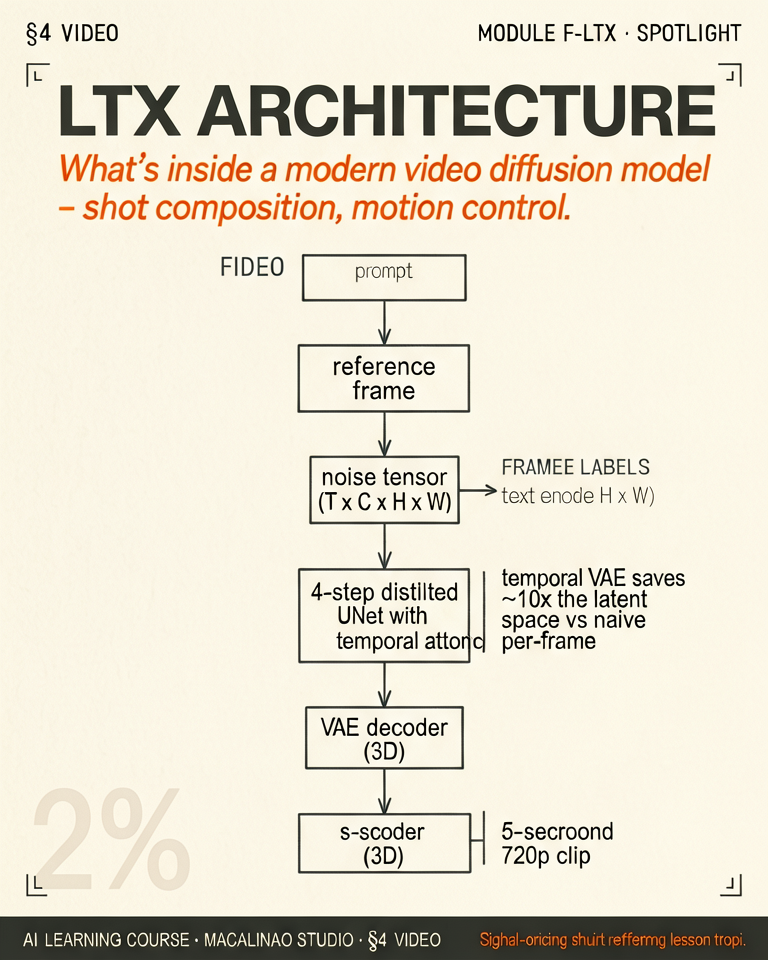
LTX-Video 0.9.x (2B and 13B variants, Nov 2024 through May 2025) was not the first open-weight video model — AnimateDiff, Stable Video Diffusion, and CogVideoX predate it. Its genuine first: faster-than-realtime DiT video generation on a single GPU — a 5-second clip at 768×512 @ 24fps in under 30 seconds on a 4090. LTX-2 (Oct 2025) added native synchronized audio, 4K output, and kept the weights open. Architecture: a DiT-style transformer trained jointly on text-to-video and image-to-video. ComfyUI is the de facto local orchestrator for open-weight video — Wan 2.x, Hunyuan, and LTX-2 all run through it.
SHOT COMPOSITION
Pacing is a prompt input, not a render setting
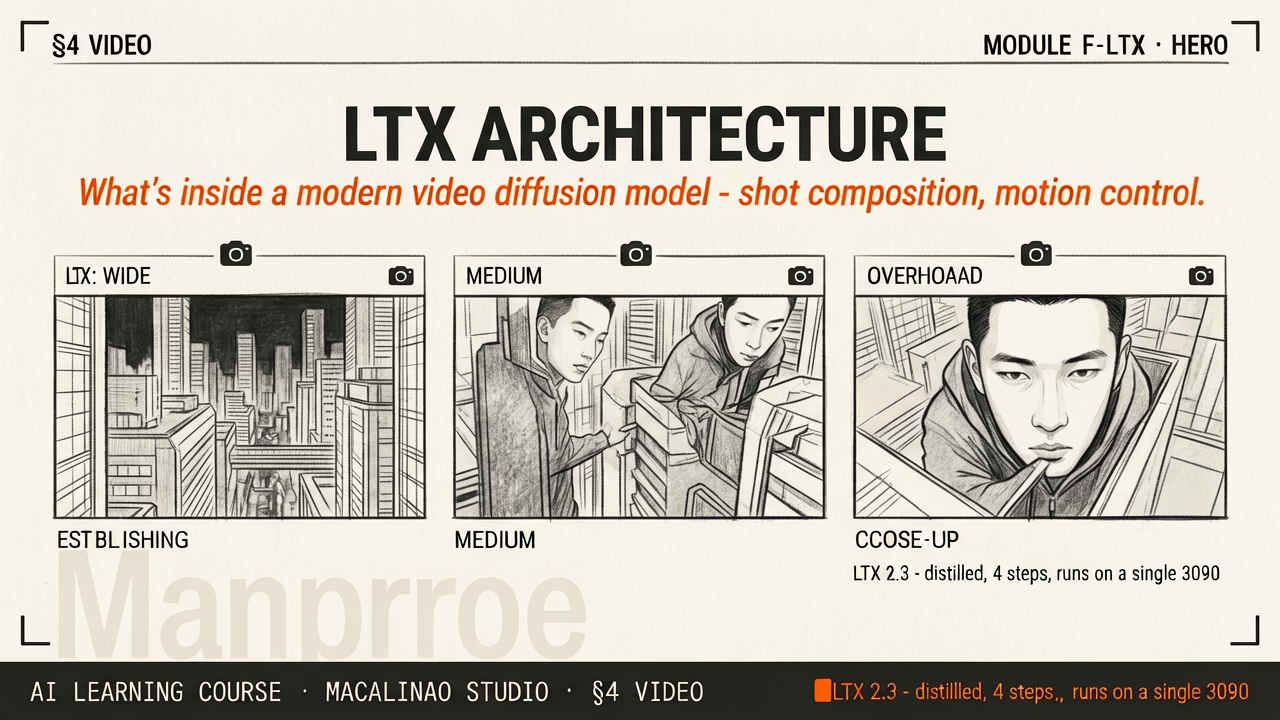
Modern video models reward thinking in shots rather than seconds. A 5-second clip can be one slow pan, three cuts, or a single dynamic action — you control this through prompt language and motion-guidance inputs. Macalinao Studio practice: write the shot in script form ("opens on wide establishing shot, slow push-in over 3 seconds, then cut to close-up") before generating.
MOTION CONTROL
Camera motion specifiers and trajectory conditioning
LTX-Video and Sora both accept motion specifiers: "static camera", "slow dolly forward", "orbit left", "crash zoom". Some systems also accept trajectory inputs — a bezier curve through 3D space that the virtual camera follows. This is the bridge between AI generation and traditional film grammar.
PRODUCTION REALITY
What ships today vs what's still hard
Ship today: native audio+video single shots — Veo 3, Sora 2, and LTX-2 all generate synchronized sound and dialogue lip-sync in one pass (native audio is LTX-2's headline feature) — plus controllable camera moves and stylized aesthetics. Still hard: multi-minute, multi-character narrative with identity and continuity holding across many cuts. The studio strategy: design around the strengths (short controlled shots, native or voiceover audio), stitch longer narratives in the edit.